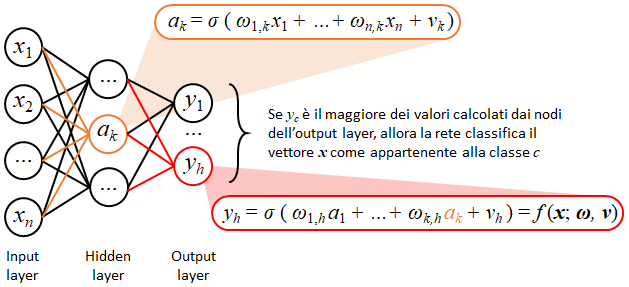
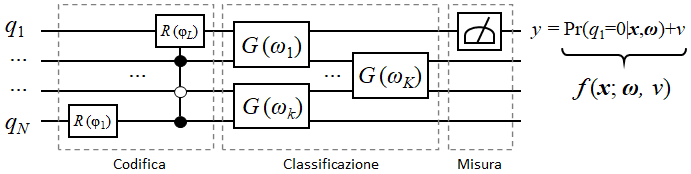
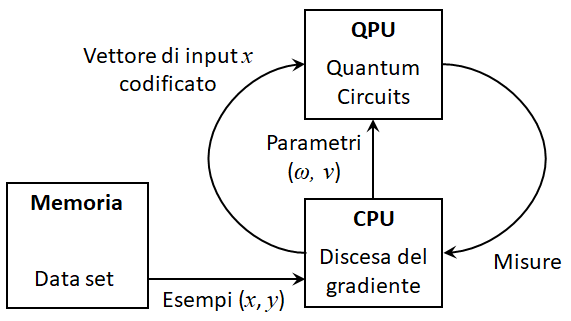
C’è un momento in cui una trasformazione tecnologica smette di essere una discussione da conferenza, da keynote o da laboratorio di innovazione, e inizia a diventare un fatto economico.
Quel momento, per il mondo SaaS, potrebbe essere arrivato all’inizio del 2026.
Il termine che lo racconta meglio è SaaSpocalypse, coniato dal trading desk di Jefferies. Jeffrey Favuzza lo ha usato per descrivere una fase di vendita molto aggressiva sui titoli software-as-a-service: una vera “apocalisse” per il settore SaaS.
Il riferimento immediato erano gli annunci e le evoluzioni di Anthropic sugli agenti AI: strumenti sempre più capaci di eseguire attività complesse, coordinare applicazioni, interagire con codice, documenti, API e sistemi enterprise. La reazione del mercato è stata violenta perché, per la prima volta, la minaccia non appariva più astratta. Gli investitori hanno iniziato a prezzare uno scenario in cui gli agenti AI non si limitano ad assistere l’utente dentro un’applicazione, ma possono sostituire intere porzioni di workflow oggi presidiate da prodotti SaaS.
Ma Anthropic, a mio avviso, non è l’origine del fenomeno. È l’evento che lo rende evidente.
La radice concettuale è precedente e può essere ricondotta a quella che considero la “profezia” di Satya Nadella del dicembre 2024. Nel podcast BG2, Nadella ha sostenuto che la stessa nozione di business application potrebbe “collassare” nell’era agentica: molte applicazioni enterprise, nella sua lettura, sono essenzialmente database CRUD con logica di business applicata sopra; se quella logica migra verso il livello AI, gli agenti diventano il luogo in cui i processi vengono realmente orchestrati.
Non siamo davanti soltanto a una nuova generazione di strumenti AI. Siamo davanti alla possibilità che il luogo in cui vive la logica di business si sposti dalle applicazioni SaaS verso un livello agentico capace di orchestrare dati, API, documenti, workflow e sistemi diversi.
Il mercato non sta punendo il software. Sta riprezzando il suo futuro
Come sempre, il mercato finanziario non fotografa semplicemente il presente. Prova ad anticipare il futuro. Il prezzo di un titolo non rappresenta soltanto i ricavi dell’ultimo trimestre o la qualità del prodotto oggi disponibile. Incorpora aspettative, rischi, scenari competitivi, probabilità di crescita e capacità prospettica di difendere i margini.
Per questo il sell-off sui titoli SaaS non va letto solo come una correzione settoriale, quanto iputtosto come un segnale della profonda trasformazione in atto che ribalta gli equilibri preorinati.
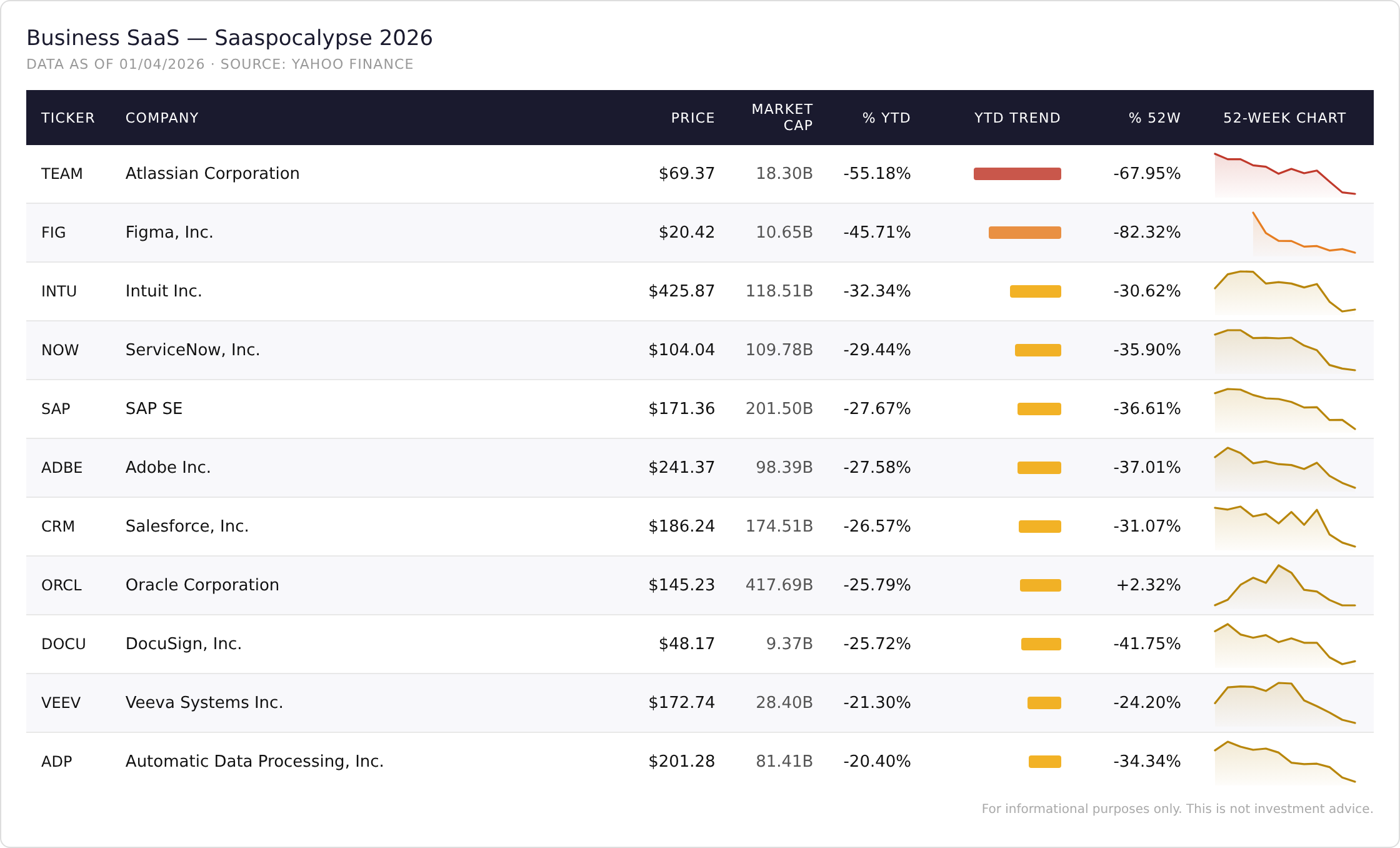
Guardando alcuni dei titoli più rappresentativi del settore, il fenomeno appare evidente. L’immagine mostra cali molto significativi per aziende come Atlassian, Figma, Intuit, ServiceNow, SAP, Adobe, Salesforce.
Il dato interessante non è solo la dimensione del calo. È la natura delle aziende colpite e la motivazione che se ne evince.
Atlassian è particolarmente esposta perché vive al centro dei processi di produzione software: issue tracking, project management, collaboration, knowledge management. Ma proprio questi processi sono tra i primi a essere ridisegnati dagli agenti AI. Se un agente può leggere il codice, interpretare una user story, generare task, aprire pull request, aggiornare documentazione, il ruolo degli strumenti tradizionali di coordinamento che vivono ai margini della codebase dove gli agenti oeprano cambia radicalmente.
Figma soffre per un motivo diverso ma simile nella sostanza. Il design non scompare, ma una parte crescente della produzione di interfacce può essere generata, trasformata o iterata da strumenti AI-native. Il valore si sposta dal canvas come luogo centrale della progettazione visuale alla capacità di trasformare requisiti, componenti, design system e codice in un flusso continuo. Ancora una volta chi non si integra nel nuovo processo produttivo è penalizzato.
Intuit rappresenta un altro fronte: il software verticale per processi amministrativi, fiscali e contabili. Qui la domanda del mercato è se un agente AI, integrato con dati, regole fiscali, documenti e sistemi bancari, possa sostituire almeno una parte del valore oggi custodito in applicazioni specializzate come TurboTax o QuickBooks.
DocuSign è esposta perché la gestione documentale e contrattuale è un caso d’uso naturale per agenti capaci di leggere, interpretare, classificare, validare, negoziare e orchestrare workflow documentali.
ServiceNow, Salesforce, SAP e Oracle sono casi più complessi. Da un lato sono incumbent con enorme profondità funzionale, relazioni enterprise consolidate e grandi basi installate. Dall’altro, il loro valore storico deriva anche dalla capacità di imporre modelli di processo standardizzati. Ed è proprio questa standardizzazione che gli agenti AI potrebbero mettere in discussione.
Il punto non è che queste aziende spariranno. Il punto è che il mercato inizia a chiedersi se il modello SaaS tradizionale, applicazione standard, workflow predefiniti, logica di business incorporata nel prodotto, pricing per utente, sia ancora il modello dominante del prossimo ciclo tecnologico.
Il contrasto con l’S&P 500 rende il segnale più forte
Il calo è ancora più significativo se considerato nel contesto generale del mercato. Molte delle aziende osservate fanno parte dell’S&P 500 o comunque appartengono al perimetro più istituzionale del software enterprise. Non stiamo parlando di piccole società speculative.
Se i titoli SaaS scendono mentre il mercato complessivo è vicino ai massimi, il messaggio è più selettivo: gli investitori non stanno uscendo dal rischio tecnologico in generale. Stanno riducendo l’esposizione a un certo tipo di software.
Questo rende la SaaS Apocalypse meno simile a una bolla che si sgonfia e più simile a una rotazione di paradigma.
Il mercato non sta dicendo che il software non vale più. Sta dicendo che potrebbe valere meno il software costruito intorno a workflow standardizzati, interfacce applicative chiuse e logiche di business intrappolate dentro piattaforme verticali.
La profezia di Nadella
È per questo che la profezia di Satya Nadella mi sembra così rilevante. Quando Nadella sostiene che la nozione stessa di business application potrebbe collassare nell’era agentica, non sta semplicemente promuovendo una nuova interfaccia conversazionale. Sta descrivendo una trasformazione architetturale.
Le business application tradizionali, nella sua lettura, sono spesso database CRUD con logica di business applicata sopra. Nell’era degli agenti, quella logica può migrare verso il livello AI: gli agenti possono leggere il contesto, decidere cosa fare, aggiornare più sistemi, coordinare transazioni e applicare regole in modo trasversale. Regole e processi che sono espressi nello stesso linguaggio con cui sono sono pensati, quello del business, quello dell’organizzazione aziendale: il linguaggio naturale.
Se la business logic si sposta verso il livello agentico, molte applicazioni enterprise perdono la posizione privilegiata che hanno avuto per decenni. Non sono più necessariamente il centro del processo. Diventano sistemi interrogabili, aggiornabili, componibili.
Nel modello SaaS tradizionale, il valore è nell’applicazione: interfaccia, workflow, dati, regole, autorizzazioni, logiche di processo. Nel modello agentico, il valore tende a spostarsi verso un altro livello: quello dell’orchestrazione intelligente, capace di usare applicazioni, API, database, documenti e knowledge base come strumenti. L’applicazione non è più necessariamente il luogo in cui vive il processo. Diventa una delle possibili superfici operative su cui l’agente agisce.
Ed è qui che la SaaS Apocalypse assume il suo significato più profondo. Non è la fine del software. È la possibile fine dell’applicazione SaaS come unico contenitore di una logica di business standardizzata e parcellizata.
Il ritorno del custom software
La conseguenza più interessante della SaaS Apocalypse non è necessariamente la fine del SaaS. È il possibile ritorno del custom software.
Per anni il SaaS ha vinto perché prometteva standardizzazione, velocità, scalabilità e minore costo di gestione. In cambio, le aziende hanno accettato un certo grado di omologazione dei processi. Il messaggio implicito era: adattate il vostro modo di lavorare al prodotto, perché il prodotto incorpora una best practice. Questa promessa ha funzionato molto bene. Ma ha anche prodotto un effetto collaterale: molte aziende hanno finito per assomigliarsi nei processi, negli strumenti e persino nei vincoli operativi.
Gli agenti AI possono invertire questa logica. Se il costo di produrre software custom scende drasticamente, e se gli agenti possono generare, testare, mantenere e modificare codice in modo più rapido ed economico, allora torna interessante costruire soluzioni specifiche, aderenti all’organizzazione reale dell’impresa.
Non si tratta di tornare al custom software artigianale, fragile e non governato. Si tratta di un custom software industrializzato, basato su codebase ordinate, automazione, test, pipeline, quality gate, documentazione strutturata e agenti AI integrati nel ciclo di sviluppo.
In questo scenario, il vantaggio competitivo non deriva più dall’adozione dello stesso SaaS usato da tutti. Deriva dalla capacità di disegnare processi differenzianti e implementarli rapidamente. Per molto tempo abbiamo considerato la standardizzazione come sinonimo di maturità. In parte lo è ancora. Ma non tutta la standardizzazione crea valore. A volte semplifica. A volte appiattisce.
L’AI agentica apre una possibilità diversa: costruire architetture che assecondano l’organizzazione, invece di costringere l’organizzazione ad adattarsi allo strumento.
Questo non significa che ogni azienda debba ricostruire da zero il proprio ERP, il proprio CRM o il proprio sistema HR. Nella maggioranza dei casi non avrebeb senso e non porterebbe un reale valore aggiunto. Ci sono però margini di competitività e innovazione dei modelli di business che richiedono che la logica di processo sia spostata fuori dalle applicazioni SaaS monolitiche e portata in un livello di orchestrazione agentica.
Le applicazioni SaaS diventano sistemi di record, sorgenti dati, servizi specializzati, superfici operative. Gli agenti diventano il livello in cui si compongono i processi.
La vera domanda per i CTO/CIO
La SaaS Apocalypse non va letta come una previsione catastrofista, ma come un avvertimento strategico.
La domanda non è quali SaaS verranno sostituiti dagli agenti, ma quanta parte della logica di business è prigioniera di piattaforme chiuse e standardizzate.
Se un processo è interamente incorporato in una piattaforma SaaS, modificarlo significa accettare i tempi, i costi e i vincoli di personalizzazione di quella piattaforma.
Se invece la logica è progressivamente spostata in un livello governato dall’impresa, agenti, workflow, API, policy, codice, automazioni, allora l’organizzazione recupera margini di libertà.
Naturalmente questa libertà ha un costo. Richiede competenze, governance, qualità del codice, sicurezza, osservabilità, responsabilità umana e una nuova disciplina di progettazione dei processi digitali. Ma è proprio su questo terreno che si giocherà la prossima sfida della competizione quando le architetture agentiche diverranno un vantaggio comparativo.
Non la fine del SaaS, ma la fine della sua inevitabilità
Il SaaS non scomparirà. Le piattaforme migliori evolveranno, incorporeranno agenti, diventeranno più aperte, più componibili, più orientate ai workflow autonomi. Salesforce, Oracle, SAP, ServiceNow, Adobe e gli altri incumbent non resteranno fermi. Anzi, proveranno a guidare questa trasformazione dall’interno.
Ma qualcosa è cambiato. Per la prima volta da molti anni, il SaaS non appare più come l’esito inevitabile di ogni trasformazione digitale. Non è più ovvio che comprare una piattaforma standard sia sempre più conveniente che costruire una soluzione su misura. Non è più ovvio che la business logic debba vivere dentro applicazioni verticali. Non è più ovvio che il processo debba adattarsi allo strumento.
La SaaS Apocalypse è il segnale che viene dal mondo finanziario di questo cambio di prospettiva in cui la personalizzazione del processo e non della piattaforma rappresenta una leva strategica in cui i le soluzioni custom tornano di moda. Non il software artigianale del passato. Ma software industrializzato, agentico, governato, misurabile, costruito intorno ai processi distintivi dell’impresa.
Il mercato ha iniziato a prezzarlo.
Ora tocca alle aziende capirlo.
]]>